The Compression Conundrum


Couple of days back I was reading about compression and how different compression algorithms work and realized that I had a flawed understanding of the fundamentals of compression algorithms. So here I am noting down what I learnt.
I will not cover any compression algorithm in this blog, will keep that for future blogs. But what I will do cover is if you want to create your own compression algorithm what should the starting point be like.
Let's step back a little
“What hath God wrought”

So our protagonist is Samuel F Morse, a successful portrait artist. But he got hooked on the idea of an electric telegraph way back in 1832. The problem at the time was that other telegraph systems needed multiple wires – a mess to manage over long distances. So Morse came up with the idea of sending electrical pulses through wire with an electromagnet attached at the end of it. A springy metal bar (the armature) is attached to the electromagnet. When the magnet pulls, the armature makes a satisfying "click" as it hits a contact.

After years of tinkering and getting partners on board (shoutout to Alfred Vail!), Morse strung a telegraph line between Washington D.C. and Baltimore. In 1844, he tapped out the now famous message, "What hath God wrought!" It wasn't just a test; imagine the hype, like sending the first ever tweet!
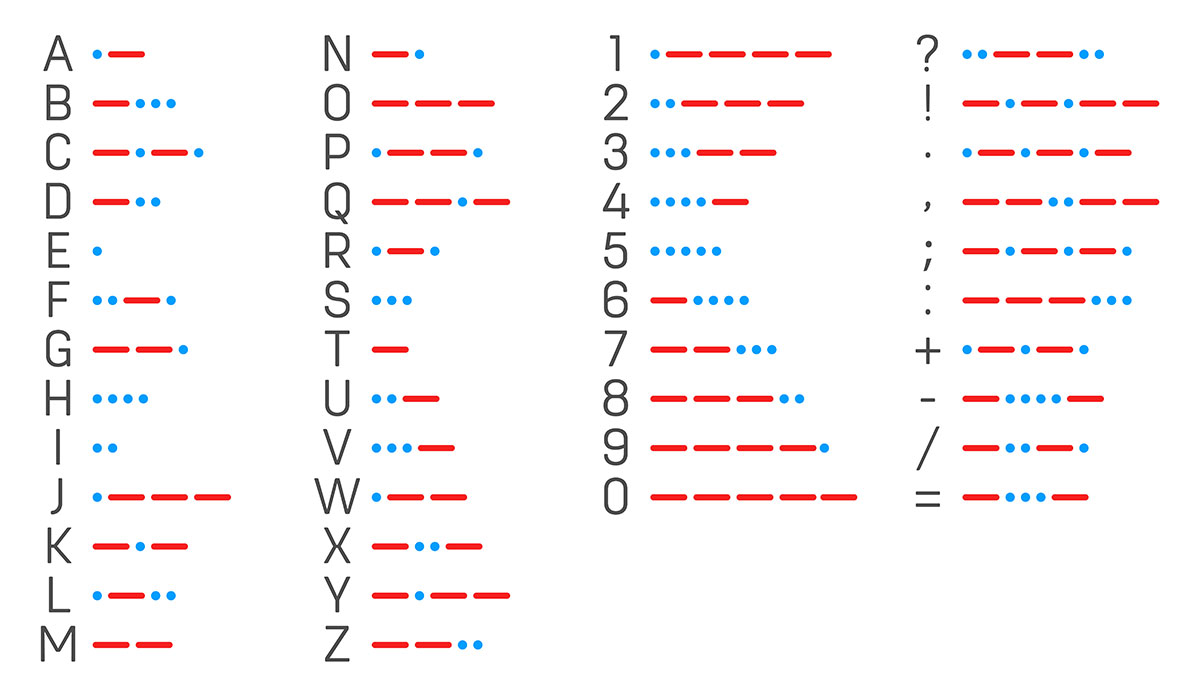
Morse's real genius wasn't just the tech; it was the code itself. Instead of a whole alphabet, he figured you could represent everything with just dots and dashes. He assigned the most common letters the shortest codes.
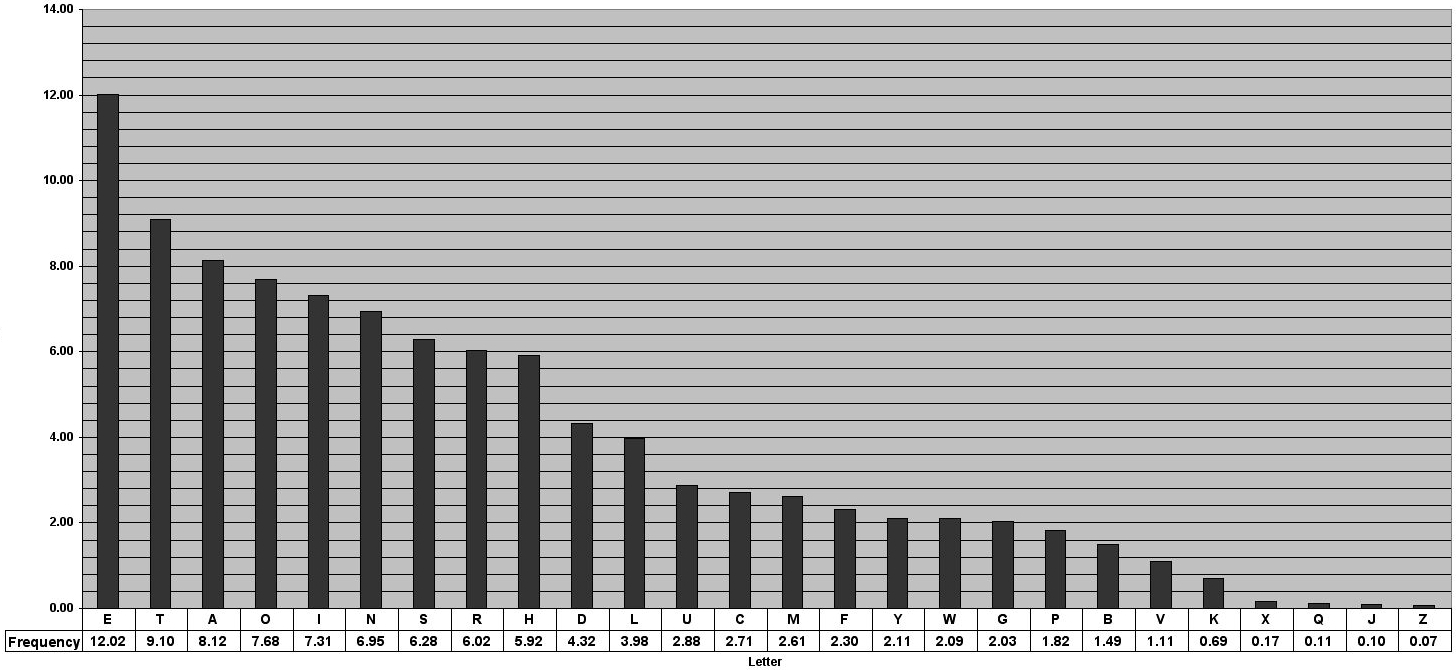
The most frequently occurring letter in the English alphabet is the letter "e," and its corresponding Morse code representation is a single dot. Similarly, the second most common letter, "t," is represented by a single dash in Morse code.
But letter’s like "z" are represented by two dashes followed by two dots. So if you had to say something like "Jazz" in Morse it would become
dot dash dash dash dot dash dash dash dot dot dash dash dot dot

But here is my question, can we call this a “compression” algorithm? Like in the last case is it performing any compression?
So, let’s understand what qualifies as a compression algorithm.
What is a compression algorithm?
Let’s say s is a string of bits of length n, and then C(s) is a function that returns a stream of bits which is a "compressed" version of s.
For a compression algorithm to work, we should be able to decompress it. It would be stupid to have an algorithm that just compresses stuff and there is no way to get back the original.
Hence, there should also exist an inverse of C(s), let’s call it D(s) such that D(C(s)) = s.
One small thing to note here is that after decompression if we get the exact uncompressed data it’s called loss-less compression.
There is another kind of compression where we expect that some information can be selectively discarded that is of less importance or less noticeable to the human eye or ear to achieve much smaller file sizes. They are called lossy compression (e.g. JPEG). Let’s just focus on loss-less compression for now.
What makes a compression algorithm good?
So, how do we know if it's a good compression algorithm? Let’s define a formula for that.
Let’s call it the compression ratio: the length of the original data divided by the length of the compressed data.
$$\text{Compression Ratio} = \frac{\text{Length of Original String}}{\text{Length of Compressed String}}$$
$$\text{i.e } \text{CR} = \frac{|s|}{|C(s)|}$$
So, if our original data is 100 bits long and after compression it becomes 50 bits long then the compression ratio is 100/50 i.e 2.
Case #1: When CR = 1
If the compression ratio is 1 then it means that the length of the data before compression is the same as the length of the data after compression. Well, then what’s the point of calling it a compression.
Case 2: When CR > 1
This is only possible when the compressed data has length less than original data. Which is supposed to be the case right? Well here is the catch.
Let’s say we have a compression algorithm C(s) which has a compression ratio greater than 1.
In the worst case:
If |s| = n, the |C(s)| will be n-1 i.e we are saying that the compression algorithm is only able to save 1 bit of space which sounds very inefficient but let’s hold on to that.
What if we apply the same compression algorithm again? Then
$$|C(C(s))| = n-2$$
If we continue doing that:
$$|C(C(C(s)))| = n-3$$
Now you see where we are leading to? Effectively after applying the same compression algorithm again and again we will be able to compress any data to 0 bits. Which is impossible, and here lies the fallacy.
Example:
Let’s take an example to understand this deeper. Let’s say we want to compress 2 bits of data. And we want to achieve at least some compression so the compressed data should be of 1 bit.
So, one possible input is 10 and we want to compress it to 1 and let’s say we want to compress 01to 0. But? What about 11or 00? We cannot compress it to 1 cause we are using 10 for that, nor can we use 0 cause we are using 01 for that.
We can actually prove this with a theorem which is one of my personal favorites: Pigeonhole Theorem.
So, for some integer n >= 1 and consider the set S of 2^n strings of length exactly n. Let's define
$$S_c = \{C(s):s \in S\}$$
$$\text{Note that, } |S_c| = |S| = 2^n$$
So, if every string in S_c has length at most n-1 then size of S_c can be at most:
$$|Sc| \leq 2^0 + 2^1 + ... + 2^{n - 1} = \sum_{i=0}^{n-1} 2^i = 2^n - 1 \text{ (contradiction)}$$
$$\text{Therefore, there exists } s \in S \text{ such that } |C(s)| > n - 1.$$
Conclusion
The conclusion from this proof is that "Compression is a Zero-Sum game". For some input to be compressed to something smaller there will be some input that will be compressed to something larger.
Don’t believe me? Try this online tool (link) to compress the following text using DEFLATE, the algorithm behind gzip which kind of runs the entire internet as of now.
ykjNyclXKMnILFYAosSivMQkheLUPIWMUXFyxAEAAAD
You will see the compressed string is larger than the original string.

Whereas if you give an input something like a text shown in the image below; we get a really good compressed result. Most of the compression algorithm used nowadays are very good at getting rid of redundancy which occurs a lot in our day to day lives. Which is why some characters in the English alphabet has higher frequency than others.

And this is the truth, most of the compression algorithms focusses on compressing inputs that are more generally available than any random stream of noise.
Therefore if you are planning to create a new compression algorithm you should ensure that your algorithm is able to achieve good compression of actual data at the expense of bad compression of random noisy data because we rarely care about them.
Getting back to where we started...
So, getting back to the question we started with, can something like Morse code be considered a compression algorithm? Well, in my opinion, it sure can. We can represent letters that show up a lot with less effort, but we have to make do with longer codes for the letters that don't show up as often, like Z, Q, and so on. And that's basically what compression is all about, as we just saw.
That spirit of squeezing the most meaning into the fewest bits? That's the heart of compression, even with today's fancy algorithms.
Comments (1)

Very clear breakdown, absolutely loved the clarity and simplicity in your explanation. Great to see you back in the blogging world!🔥⭐