One Instruction to Rule Them All: Exploring OISC


Table of contents
Background
As software developers, our daily routine revolves around crafting programs in familiar languages such as JavaScript, C++, Python, Rust, Java, and more. We immerse ourselves in mastering the syntax of these languages and then put the keywords such that it achieves our business logic. But the question is: How does the computer comprehend this diverse array of languages?
Most of the languages that we usually come under the category of High-Level Language. They are high-level in the sense they provide a higher level of abstraction and allow us to write more "human-readable" code.
Let's take a look at this super fancy C Code, which most of you have written at some point in your career as a developer:
#include <stdio.h>
void main() {
printf("hello world");
}
A computer doesn't understand these words like "printf", "void", "main". They are meant for us humans to write code faster and more efficiently. Once the compiler compiles the code into Machine Language it looks like this:
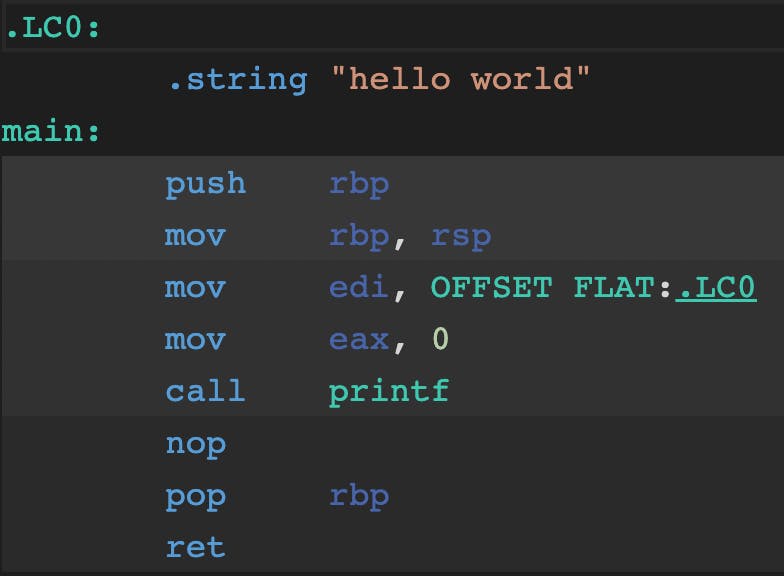
Note: This assembly code is for Linux using the x86 architecture. The actual machine code can vary based on the target system.
You can notice the words like push, mov, call, nop, pop etc. These are commands that the CPU can understand and they all belong to something called an instruction set.
It serves as an interface between the hardware and the software, allowing us to write software that can run on a specific architecture.
The instruction set of a processor typically includes a variety of instructions that can perform operations such as arithmetic, logic, data movement, control flow, and more. Here are some common types of instructions found in an instruction set:
Arithmetic Instructions:
- Addition (
ADD), subtraction (SUB), multiplication (MUL), division (DIV), etc.
- Addition (
Logic Instructions:
- Logical AND (
AND), logical OR (OR), logical XOR (XOR), bitwise operations, etc.
- Logical AND (
Data Movement Instructions:
- Load (
LOAD), store (STORE), move (MOV), etc.
- Load (
Control Flow Instructions:
- Jump (
JMP), conditional jump (JZfor zero,JNZfor not zero, etc.), subroutine call and return, etc.
- Jump (
Comparison Instructions:
- Compare (
CMP), test for equality (EQ), test for greater than (GT), etc.
- Compare (
Input/Output Instructions:
- Input (
IN), output (OUT), system calls, etc.
- Input (
The specific instructions available in an instruction set can vary between different CPU architectures. For example, x86 and ARM are two different instruction set architectures commonly used in today's processors, and they have distinct sets of instructions.
In today's world, we have it easy, we just have to write the high-level code and the compiler translates the high-level code into the machine code instructions that the processor understands, based on the instruction set architecture.
Although, understanding the instruction set is essential for low-level programming, optimization, and when working with assembly language or writing programs that directly interact with hardware.
In this blog, I will talk about one specific kind of Instruction Set which I found really fascinating.
OISC
OISC stands for One Instruction Set Compiler (OISC). It is also called Single Instruction Programming Language or Ultimate Reduced Instruction Set Computer (URISC).
As the name suggests, this instruction set has just one instruction.
Okay, but you might think, what's so special about that? Anyone can create an instruction set that has just one instruction and call it an OISC.
Well, not really. Most mainstream programming languages are able to solve such a wide variety of problems and computations because they are all Turing Complete. If a programming language is Turing complete, it means that it can theoretically compute anything that is computable, given enough time and resources. (I'll do a separate blog on Turing Completeness, but for the time being, you can understand it like a test for programming languages)
Here is a movie recommendation: "The Imitation Game" based on the life of Alan Turing.

The OISC that I am going to talk about is also Turing complete, but the best part is unlike the Turing machine it doesn't need to have an infinite memory model. Hence, it is equivalent to a real computer than a Turing machine. And the instruction is subleq (Subtract and branch if less than or equal to zero).
For any instruction to be Turing Complete (or in simple words be able to compute most complex computations) it needs to have some sort of conditional branching. You can imagine this to be something like
if <condition>
goto <branch>
Now, these machines can be categorized into 3 types:
Bit manipulating machines
Transport triggered machines
Arithmetic-based machines
mov is another such instruction. The mov instruction copies the data item referred to by its second operand (i.e. register contents, memory contents, or a constant value) into the location referred to by its first operand (i.e. a register or memory).
mov a, b
//it is equivalent to
*a = *b;
This mov instruction is Turing complete and comes under 2. Transport Triggered Machine. There is an amazing repo that showcases the fact that any C program can be compiled into a program written only using mov instructions. You can check it out here.
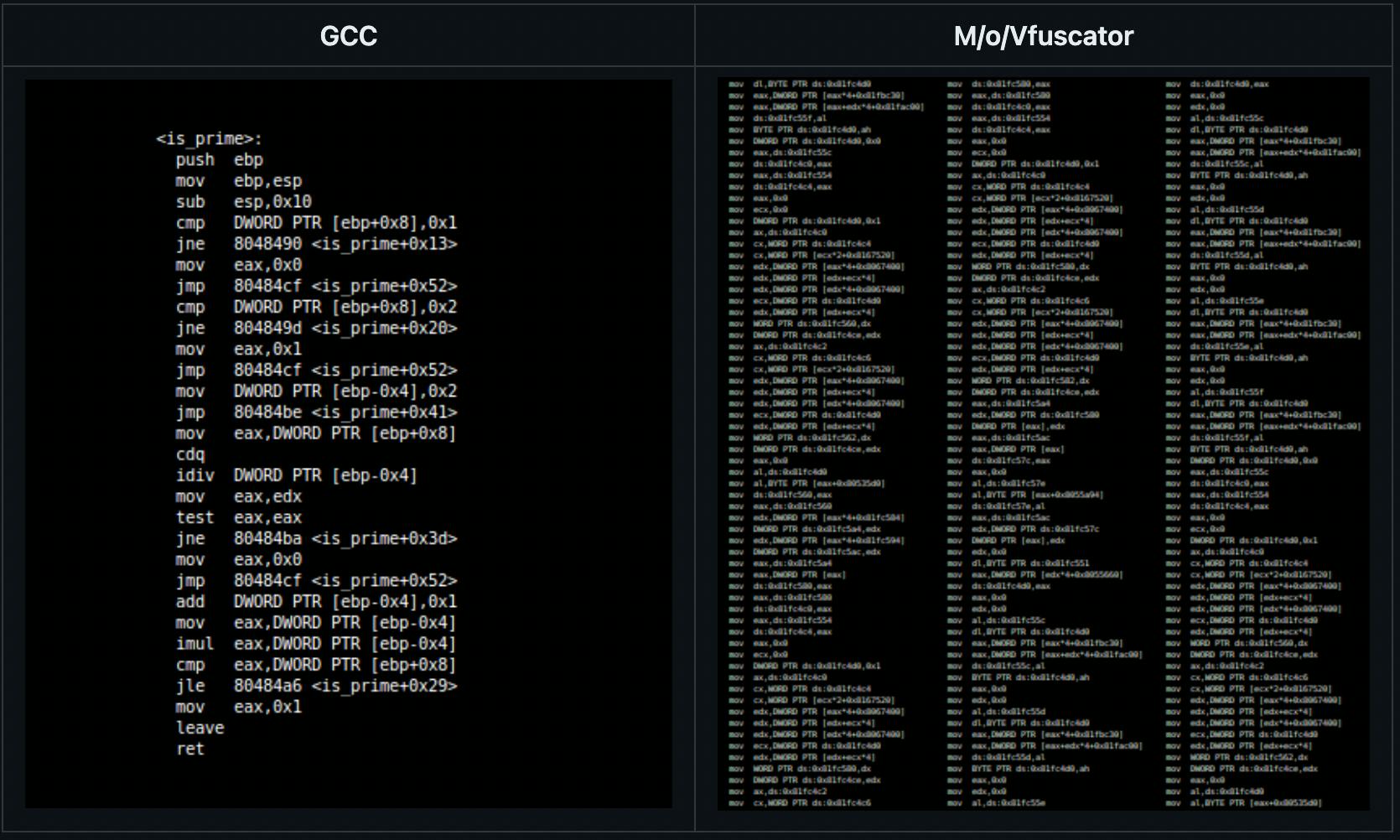
On the left, you have the code in Assembly, and on the right, you have the same code which does the exact same thing but it only contains the instruction mov.
Arithmetic-based Turing-complete machines use an arithmetic operation and a conditional jump. This is what subleq does.
Let's simplify the subleq operation. If we do subleq a, b, c it comes down to:
Mov[b] = Mov[b] - Mov[a];
if (Mov[a] <= 0) goto c;
So, you can see there is a basic arithmetic operation and one conditional branching, (we already mentioned that it is required to be Turing complete). There is a syntactic sugar for the same which goes like this
subleq a, b ; Mem[b] = Mem[b] - Mem[a]
; goto next instruction
Here we basically drop the c which means we aren't branching anywhere but rather moving on to the next instruction. Now the big question. Is this instruction enough? Well as it turns out. Yes, it is.
Let's look at some programs using this instruction:
Example 1
; initially *z = 0
subleq a, z
subleq z, b
subleq z, z
let's break this down
//initally
*z = 0;
//line 1
*z = *z - *a // since *z=0, this line boils down to
*z = -*a
//line 2
*b = *b - *z // *z = -*a, this line boils down to
*b = *b - (- *a)
*b = *b + *a
//line 3
*z = *z - *z
*z = 0 //we started with *z=0 and ended with *z=0
What we see is *b = *b + *a i.e. this 3-line instruction performs addition.
The reason we use (*) before a, b, z is because those represent memory addresses and *a represents the value in that particular memory block
The reason the last line is important is because we have to ensure we do not end up changing the values that we are not dealing with, here we were just dealing with a and b. z was initially 0 and finally should also be 0. In other words, there shouldn't be any side effects.
Not just addition other instructions can also be implemented with subleq instruction as well.
Example 2
; initially *z=0
subleq b, b
subleq a, z
subleq z, b
subleq z, z
You can work these out and you will come to the conclusion that it ends up assigning the value of a to b.
Or you can apply 200IQ and notice that this is exactly the same as the previous one, only a new instruction subleq b, b was added to the beginning, we know the other 3 lines implement this *b = *b + *a and the first line is basically *b=0 , hence what we finally get is *b= 0+*a i.e. *b=*a.
Example 3
subleq z, z, c
This is very basic, it will just jump to the branch c.
The interesting thing is this programming language with this one instruction is equally powerful to any other programming language like C++, Java .etc.
It may not be very efficient and easy to write but in the end, all of these come under the class of Turing Complete. Yet there are some interesting benefits to employing a one-instruction computer. For example, hardware-level functionality is simplified when implemented around a single instruction. This greatly simplifies the underlying implementation, as the same functional element is repeatedly used to form the processor core. Another advantage is that since all the instructions are the same, the instruction decoder circuitry and complexity can be eliminated.
Why bother about OISC?
OISC architectures provide an excellent paradigm for implementing traditional von Neumann computers using non-traditional materials. Simply put, a practical computer can be built by massive scaling of simple, single instruction elements. Embracing OISC challenges us to strip away the layers of abstraction, inviting a deeper exploration of the foundational principles that govern all programming.

I hope you found my blog informative. If you have any feedback share it in the comments. You can sign up for the Hashnode newsletter to get notified every time I post a blog. Learn more about me at arnabsen.dev/about. Have a nice day.