Graph Databases 101: Guide to Understanding Connected Data


Traditional databases often struggle to model and query complex interconnected data. This is where graph databases come in, offering a powerful way to represent and navigate relationships. In this blog series, we will dive into a high level idea of what's all the fuss about graph databases.
A quick disclaimer: Don't worry if you're not a graph theory expert. You can still follow and discover the potential of this technology.
Traditional databases: a world of Records and Transactions
The early days of computing were dominated by structured data like inventory records and financial transactions. Relational databases, with their tables and rows, were the perfect tool for this kind of information. These data were mainly discrete and traditional relational databases would suffice such kind of data.
However, the internet revolutionized the data landscape. Today, major players like Google, Meta, and X deal with vast amounts of interconnected data.
Take Facebook, for example. The entire platform is built on a social graph, a web of relationships where Alice is friends with Bob, Bob is friends with Charlie, etc. Similarly, the "follows" relationship on Instagram/X forms another kind of graph. Google's search engine relies on a knowledge graph to understand the connections between websites and the information they contain.

While relational databases are still incredibly useful, they struggle when it comes to modeling and querying these intricate relationships. We’ll take a closer look at these cases.
Representing Relationships
Relationships within interconnected data are best described using graphs.
Let's illustrate this with a simple Twitter example:
Alice follows Bob
Alice follows Charlie
Bob follows Charlie
Charlie follows Bob
Alice follows Dave
Dave follows Charlie
Bob follows Dave
If we were to ask, "How many people does Bob follow?", we'd have to scan through all the records to count them.
But if we visualize this data as a graph: The answer becomes immediately clear.

We can also see that Charlie is the most followed person in this dataset. Graphs provide a powerful way to visualize and analyze relationships, making them a natural fit for representing interconnected data.
While graph theory has existed since the 18th century (with contributions from mathematicians like Euler), it wasn't until the early 2000s that graph databases started gaining traction in the commercial world. Companies like Neo4j were among the first to offer graph database solutions, paving the way for wider adoption. Today, many popular graph databases are available, including Amazon Neptune and ArangoDB. Beyond social networks, graph databases are used in various applications like fraud detection, recommendation engines, and knowledge graphs.

Terminologies for Graph Database
Graph databases are based on a model called Labeled Property Graphs.
Let's explore the key components of this model
Nodes
Nodes represent individual entities in the data. They can be people, places, things, or any other object you want to model. Each node can have an optional set of properties stored as key-value pairs. For example, a node representing a user might have properties like:
{
id: 1001
name: Alice,
handle: alice123
}
Labels
Nodes can also have one or more labels, which categorize them based on their characteristics. For example, in a social network graph, some nodes might be labeled as "user," while others might be labeled as "post." Labels are essential for querying and filtering data efficiently.
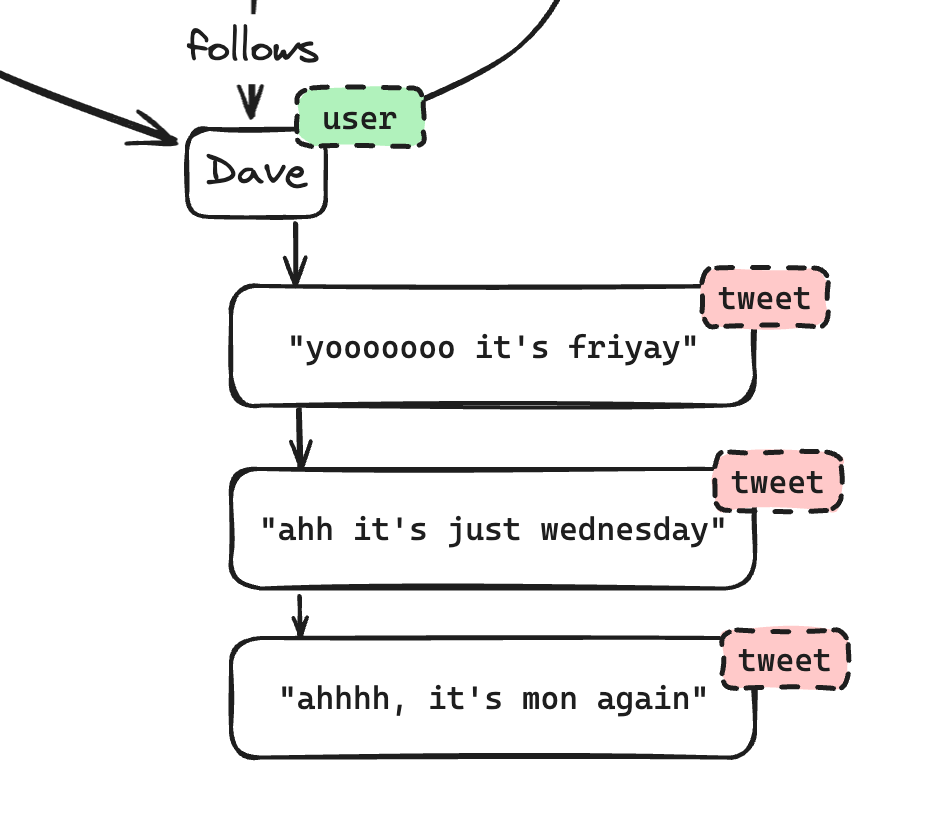
Relationships
Relationships define how nodes are connected. They are inherently directional, meaning that "Alice follows Bob" is not the same as "Bob follows Alice." Relationships can also have optional properties. In our Twitter example, a "follows" relationship might have a property like { created_at: 2024-05-01 } signifying that the person started following from 1st May 2024.
Where Graph Databases Shine
Imagine trying to answer the following query using our Twitter example in a relational database: "How many people does Alice follow who have at least 100 followers and have all posted at least 3 tweets with more than 10 likes?" The SQL query would be a nightmare of multiple joins and subqueries, likely taking a significant amount of time to execute.
In contrast, a graph database could answer this question with a simple traversal, following the relationships from Alice's node to her followers, then to their followers, and finally to their tweets. This traversal could be orders of magnitude faster than the equivalent relational query.
Graph databases also excel at uncovering unexpected insights. While relational databases are optimized for structured queries based on a predefined schema, graph databases allow for more exploratory analysis. They're not just about answering known questions; they're about discovering relationships and patterns you didn't even know existed.
Furthermore, graph databases offer flexibility. Making changes to the schema or adding new types of relationships is often much easier than in a relational database, where complex migrations might be required.
In essence, graph databases are the tool of choice when relationships between data points are as crucial as the data itself. If your data is highly interconnected and you need to perform complex relationship-centric queries or explore your data in new ways, graph databases might be the perfect fit. But if it’s not the case, then relational databases should be your goto choice.
Native Graph Processing
This way of modeling data is consistent across various graph database implementations, but there are different ways to encode and represent graphs in a database engine’s main memory. A graph database can have native processing capabilities if it exhibits a property called index-free adjacency.
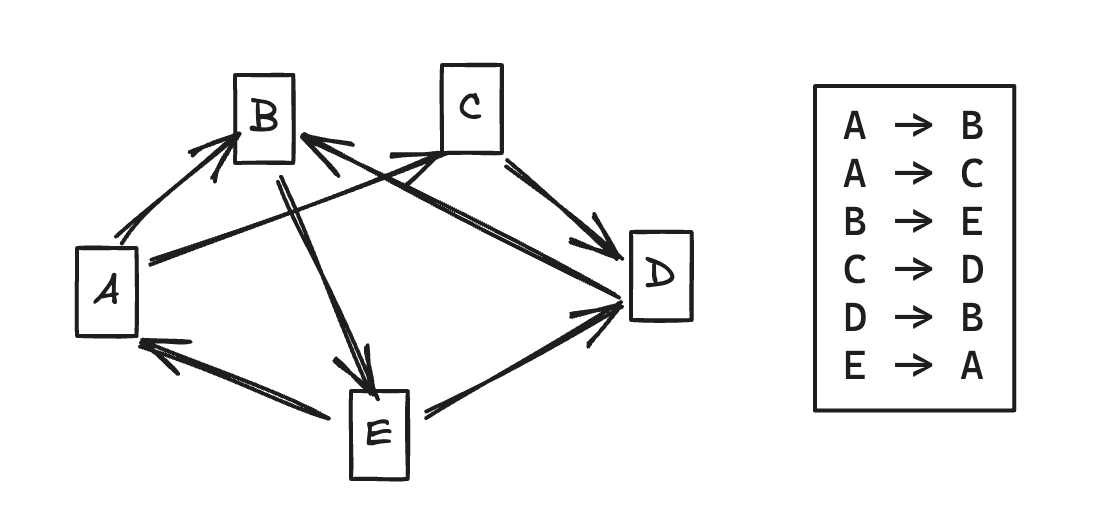
How do we represent which nodes are adjacent to each other? In a graph, two nodes are adjacent if they are directly connected by a relationship. In non-native graph processing, an index might be used to look up adjacent nodes, similar to how a relational database uses indexes for faster query performance. However, this introduces overhead and can limit the speed of graph traversals.
So, even on the surface it is still a graph based model, it’s just that there exists a global index to fetch the adjacent nodes.
In contrast, native graph processing engines use index-free adjacency. Each node directly stores references (like pointers) to its neighboring nodes. Think of it like a linked list where each element points to the next. This allows for extremely fast traversal, as there's no need to consult a global index.
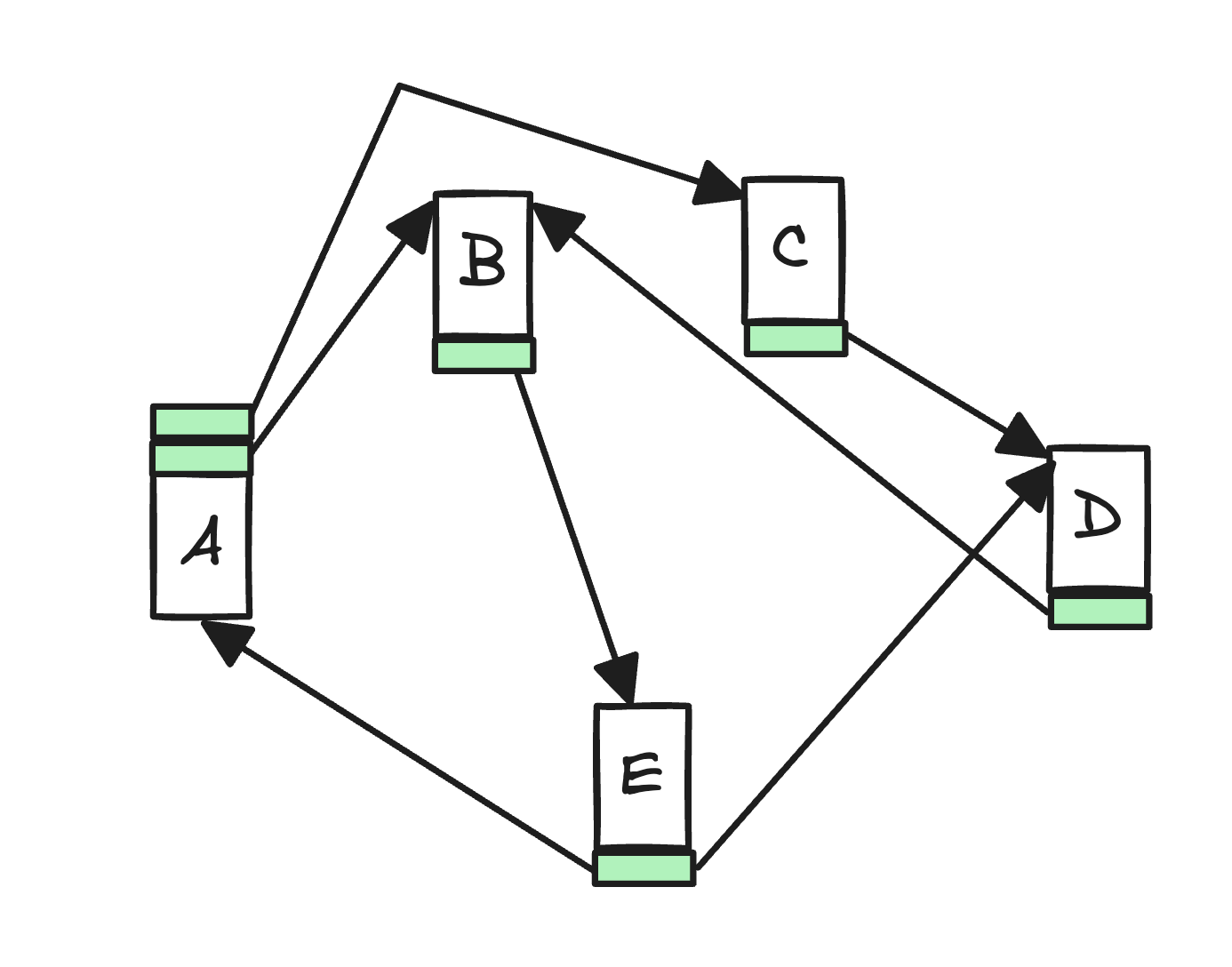
There are multiple advantages of having index-free adjacency
Faster Lookups
Depending on the implementation, index lookups could be O(log n) in algorithmic complexity versus O(1) for looking up immediate relationships. To traverse a network of m steps, the cost of the indexed approach, at O(m log n), dwarfs the cost of O(m) for an implementation that uses index-free adjacency.
Simpler Queries
Furthermore if we were to ask “how many followers does node B have?” In non-native graph processing we have to iterate through all the indices to get the count. To avoid that, we have to instead maintain a reverse-index.
Whereas with native graph processing we can just look into the incoming edges to node B and we will know the answer.
While index-free adjacency offers significant advantages, it's worth noting that it can lead to higher memory usage for dense graphs where nodes have many connections. However, for many real-world use cases, the performance benefits far outweigh this potential drawback.
Conclusion
In this introduction to graph databases, we've explored how they differ from traditional relational databases, their core terminology (nodes, relationships, properties), and the concept of native graph processing. In the upcoming posts, we'll delve deeper into the inner workings of graph databases, exploring how Neo4j and other systems store and manage graph data on disk.
If you found this post helpful, please like and follow for more insights into the exciting world of graph databases.
Comments (4)


Waiting for the next post of this series, really interesting topic!

This is really well explained and detailed, great job! The insights are super valuable. Can't wait for the next article in the series, keep them coming!

looks like you focused on midmarket vendors and not enterprise.